一、EGES [2018]
《Billion-scale Commodity Embedding for E-commerce Recommendation in Alibaba》
互联网技术不断重塑商业格局,如今电商无处不在。阿里巴巴是中国最大的电商平台,它使得全世界各地的个人或公司都可以在线开展业务。阿里巴巴拥有
10亿用户,2017年的商品交易总额(Gross Merchandise Volume: GMV)为37670亿元,2017年的收入为1580亿元。在著名的 “双十一” 这个中国最大的网络购物节,2017年的GMV约为1680亿元。在阿里巴巴的各类在线平台中,最大的在线consumer-to-consumer: C2C平台淘宝贡献了阿里巴巴电商总流量的75%。淘宝拥有
10亿用户和20亿item(即商品),最关键的问题是如何帮助用户快速找到需要的、感兴趣的item。为了实现这一目标,基于用户偏好(preference)从而为用户提供感兴趣的item的推荐技术成为淘宝的关键技术。例如,手机淘宝首页(如下图所示)是根据用户历史行为而通过推荐技术生成的,贡献了总推荐流量的40%。此外,推荐贡献了淘宝的大部分收入和流量。总之,推荐已经成为淘宝和阿里巴巴的GMV和收入的重要引擎。下图中,用虚线矩形框突出显示的区域是针对淘宝上十亿用户的个性化。为了更好的用户体验(user experience),我们还生成了吸引人的图像和文本描述。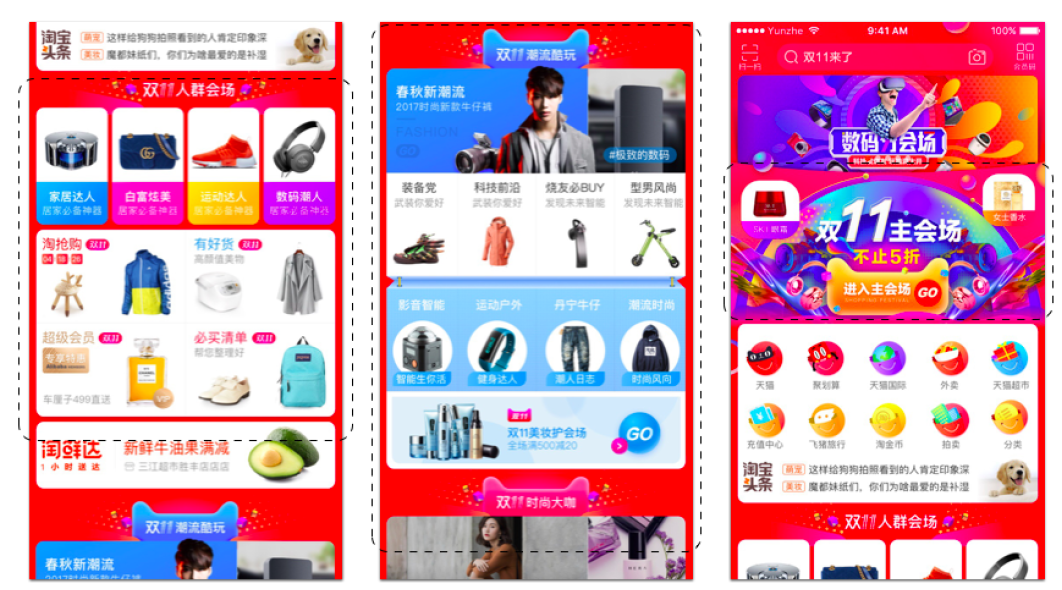
尽管学术界和工业界的各种推荐方法取得了成功,例如协同过滤(
collaborative filtering: CF)、基于内容的方法、基于深度学习的方法,但是由于用户和item的十亿级的规模,这些方法在淘宝上面临的问题变得更加严重。推荐系统在淘宝面临三大技术挑战:可扩展性(
scalability):尽管很多现有的推荐方法在较小规模的数据集(即数百万用户和item)上运行良好,但是在淘宝的、大得多的数据集(即10亿用户和20亿item)上无法运行。稀疏性(
sparsity):由于用户往往只与少量item进行交互,因此很难训练出准确的推荐模型,尤其是对于交互次数很少的用户或item。这通常被称作稀疏性问题。冷启动(
cold start):在淘宝,每小时都有数百万新的item不断上传。这些item没有用户行为。处理这些item或预测用户对这些item的偏好具有挑战性,这就是所谓的冷启动问题。稀疏性和冷启动都是因为数据太少导致的,冷启动是完全没有历史交互,而稀疏性是只有很少的历史交互。
为了解决淘宝的这些挑战,我们在淘宝的技术平台中设计了一个两阶段的推荐框架。第一阶段是
matching,第二阶段是ranking。在
matching阶段,我们为每个用户,根据该用户的历史交互的每个item生成相似item的候选集合(candidate set)。在
ranking阶段,我们训练一个深度神经网络模型,该模型根据每个用户的偏好对候选item进行排序。
由于上述挑战,在这两个阶段我们都必须面对不同的独特问题(
different unique problems)。此外,每个阶段的目标不同,导致技术解决方案也不同。在论文《Billion-scale Commodity Embedding for E-commerce Recommendation in Alibaba》中,我们专注于如何解决matching阶段的挑战,其中核心任务是根据用户的行为计算所有item之间的pairwise相似性(similarity)。在获得item的pairwise相似性之后,我们可以生成候选item的集合,以便在ranking阶段进一步个性化。为了实现这一点,我们提出从用户的行为历史构建一个
item graph,然后应用SOTA的graph embedding方法来学习每个item的embedding,我们称之为Base Graph Embedding: BGE。通过这种方式,我们可以根据从item embedding向量的内积计算出的相似性来生成候选item集合。注意,以前的工作使用CF-based方法来计算item之间的相似性,而CF-based方法仅考虑用户行为历史中item的共现(co-occurrence)。但是在我们的工作中,通过在item graph中使用随机游走,我们可以捕获item之间的高阶相似性。因此,我们的方法优于CF-based方法。然而,在很少交互、甚至没有交互的情况下学习
item的精确embedding仍然是一个挑战。为了缓解这个问题,我们提出使用辅助信息(side information)来提升(enhance)embedding过程,我们称之为Graph Embedding with Side information: GES。例如,属于同一类目(category)或同一品牌(brand)的item在embedding空间中应该更接近。通过这种方式,我们可以在很少交互甚至没有交互的情况下获得item的精确embedding。然而,在淘宝中有数百种类型的辅助信息,如类目、品牌、价格等等。直观而言,不同的辅助信息对学习
item的embedding应该有不同的贡献。因此,我们进一步提出了一种在学习带辅助信息的embedding时的加权机制,称作Enhanced Graph Embedding with Side information: EGES。本文主要贡献:
基于淘宝多年的实践经验,我们设计了一种有效的启发式(
heuristic)方法,从淘宝上十亿用户的行为历史构建item graph。我们提出了三种
embedding方法(BGE、GES、EGES)来学习淘宝中20亿item的embedding。我们进行离线实验以证明BGE、GES、EGES和其它embedding方法相比的有效性。为了在淘宝中为十亿级用户和
item部署所提出的方法,我们在我们团队搭建的XTensorflow: XTF平台上构建了graph embedding system。我们表明,所提出的框架显著提高了手机淘宝App的推荐性能,同时满足了双十一当天训练效率和serving的即时响应(instant response)的需求。
相关工作:这里我们简要回顾
graph embedding、带辅助信息的graph embedding、以及用于推荐的graph embedding的相关工作。Graph Embedding:graph embedding算法已经作为一种通用的网络表示方法,它们已被用于很多实际application。在过去的几年里,该领域有很多研究专注于设计新的embedding方法。这些方法可以分为三类:LINE等分解方法尝试近似分解邻接矩阵并保留一阶和二阶邻近性。深度学习方法增强(
enhance)了模型捕获图中非线性的能力。基于随机游走的技术在图上使用随机游走来获得非常有效的
node representation,因此可用于超大规模网络。
在本文中,我们的
embedding框架基于随机游走。带辅助信息的
Graph Embedding:上述graph embedding方法仅使用网络的拓扑结构,存在稀疏性和冷启动的问题。近年来,很多工作试图结合辅助信息来增强graph embedding方法。大多数工作基于具有相似辅助信息的节点在embedding空间中应该更接近的假设来构建他们的任务。为了实现这一点,《Discriminative deep random walk for network classification》和《Max-margin deepwalk: Discriminative learning of network representation》提出了一个联合框架来优化带分类器函数的embedding目标函数。论文《Representation learning of knowledge graphs with hierarchical types 》进一步将复杂的知识图谱嵌入到具有层级结构(hierarchical structure)(如子类目)的节点中。此外,也有一部分工作将节点相关的文本信息融合到
graph embedding中。另外,《Heterogeneous network embedding via deep architectures》提出了一个深度学习框架来为异质graph embedding同时处理文本和图像特征。在本文中,我们主要处理淘宝中
item相关的离散辅助信息,例如类目(category)、品牌(brand)、价格等,并在embedding框架中设计了一个hidden layer来聚合不同类型的辅助信息。用于推荐的
Graph Embedding:推荐一直是graph embedding最流行的下游任务之一。有了node representation,就可以使用各种预测模型进行推荐。在
《Personalized entity recommendation: A heterogeneous information network approach》和《Meta-graph based recommendation fusion over heterogeneous information networks》中,user embedding和item embedding分别在meta-path和meta-graph的监督下在异质信息网络(heterogeneous information network)中学习。《Personalized entity recommendation: A heterogeneous information network approach》为推荐任务提出了一个线性模型来聚合embedding。《Meta-graph based recommendation fusion over heterogeneous information networks》提出将分解机(factorization machine: FM)应用于embedding以进行推荐。
《Collaborative knowledge base embedding for recommender systems》提出了一个联合embedding框架,从而为推荐任务学习graph, text, image的embedding。《Scalable graph embedding for asymmetric proximity》提出了graph embedding来捕获节点推荐(node recommendation)的非对称相似性(asymmetric similarity)。在本文中,我们的
graph embedding方法被集成到一个两阶段推荐平台中。因此,embedding的性能将直接影响最终的推荐结果。
1.1 模型
我们首先介绍
graph embedding的基础知识,然后详细说明我们如何根据用户的行为历史来构建item graph,最后我们研究了在淘宝中学习item embedding的方法。Graph Embedding:这里我们概述了graph embedding,以及最流行的一种graph embedding方法 :DeepWalk。我们是在DeepWalk的基础上提出了matching阶段的graph embedding方法。给定一个图
graph embedding是为每个节点representation,其中受到
word2vec的启发,Perozzi等人提出了DeepWalk来学习图中每个节点的embedding。他们首先通过在图中运行随机游走来生成节点序列,然后应用Skip-Gram算法来学习图中每个节点的representation。为了保持图的拓扑结构,他们需要解决以下最优化问题:其中:
1-hop或者2-hop节点集合。
接下来,我们首先介绍如何根据用户的历史行为构建
item graph,然后提出基于DeepWalk的graph embedding方法,从而为淘宝中的20亿item生成低维representation。构建
Item Graph:这里,我们将详细说明从用户历史行为构建item graph。实际上,用户在淘宝上的行为往往是连续的,如图
(a)所示。以往的CF-based方法仅考虑item的共现(co-occurrence),而忽略了可以更准确地反映用户偏好的序列信息(sequential information)。 然而,不可能使用用户的全部历史记录(来作为一个序列),有两个原因:条目(
entry)太多,导致计算成本和空间成本太高。用户的兴趣会随着时间而漂移(
drift)。
因此在实践中,我们设置了一个时间窗口,仅选择用户在窗口内的行为。这称为
session-based用户行为。根据经验,时间窗口的大小为一个小时。例如图(a)中,包含用户session、用户session、用户session。在我们获得
session-based用户行为之后,如果两个item相连地(consecutively)出现,则它们通过有向边连接。如下图(b)所示:item D和item A相连,因为用户item D和item A。这种图构建方式捕获了序列关系。如果是连接
session内的任意两个item,则捕获了共现关系。利用淘宝上所有用户的协同行为(
collaborative behaviors),我们根据所有用户行为中两个相连item的出现总数为每条边itemitemitem graph可以基于淘宝中所有用户的行为来表示不同item之间的相似性。图(b)为根据图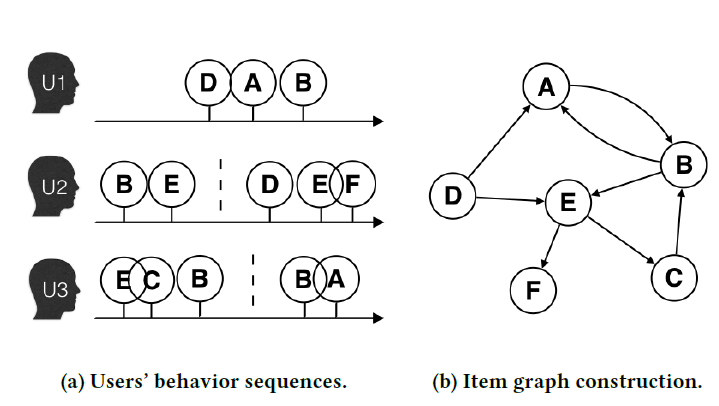
在实践中,我们在抽取用户行为序列之前需要过滤掉无效数据(
invalid data)和异常行为(abnormal behaviors),从而消除噪声。目前,以下行为在我们的系统中被视为噪声:如果点击之后停留的时间少于一秒钟,那么点击可能是无意的,则需要移除。
淘宝上有一些 “过度活跃” 的用户,他们实际上是作弊用户(
spam users)。根据我们在淘宝上的长期观察,如果单个用户在不到三个月内,总购买数量大于1000或者总点击数量大于3500,则该用户很可能是作弊用户。我们需要过滤掉这些用户的行为。淘宝的零售商不断地更新商品的详细信息。在极端情况下,一个商品在经过长时间的更新之后,在淘宝上可能变成完全不同的商品,即使它们具有相同的商品
id。因此,我们删除了这些id相关的item(即更新前后,该id代表了完全不同的商品)。
Base Graph Embedding: BGE:在得到有向加权图(记作DeepWalk来学习每个节点在embedding。令
Skip-Gram算法。随机游走的转移概率定义为:其中
outlink邻居的集合,即outedge)指向的节点集合。通过运行随机游走,我们可以生成许多序列,如下图
(c)所示。然后我们应用Skip-Gram算法(如图(d)所示)来学习节点embedding,从而最大化随机游走序列中两个节点的共现概率(occurrence probability)。这导致了以下的最优化问题:其中
使用独立性假设,我们有:
其中:
应用负采样技术,则最优化问题可以转化为:
其中:
sigmoid函数。根据经验,负样本规模越大则最终结果越好。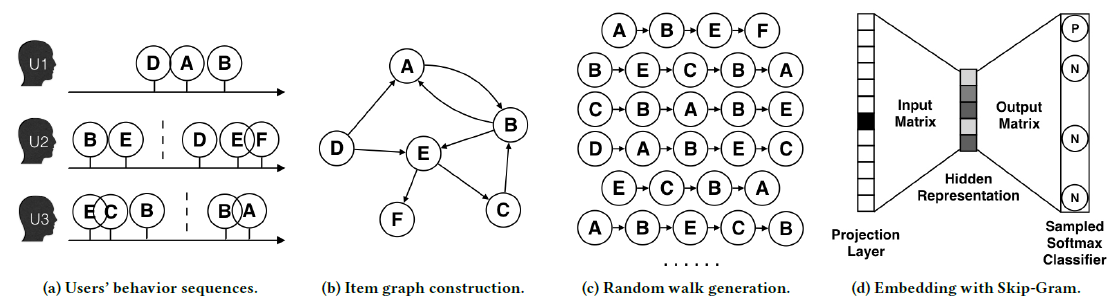
Graph Embedding with Side information: GES:通过应用上述embedding方法,我们可以学习淘宝中所有item的embedding,从而捕获用户行为序列中的高阶相似性。而这种高阶相似性在以前的CF-based方法中被忽略。然而,学习 “冷启动”item(即那些没有用户交互的item)的accurate embedding仍然具有挑战性。为了解决冷启动问题,我们提出使用附加到冷启动
item的辅助信息(side information)来增强(enhance)BGE。在电商推荐系统的上下文中,辅助信息指的是item的类目(category)、门店(shop)、价格(price)等信息,这些信息在ranking阶段被广泛用作关键特征,但是在matching阶段很少使用。我们可以通过在graph embedding中融合辅助信息来缓解冷启动问题。例如,优衣库(相同门店)的两件帽衫(相同类目)可能看起来很像;喜欢尼康镜头的用户也可能对佳能相机(相似类目、相似品牌)感兴趣。这意味着具有相似辅助信息的item应该在embedding空间中更接近。基于这个假设,我们提出了如下图所示的GES方法。我们使用
item或辅助信息的embedding矩阵,具体而言:item embedding矩阵。embedding矩阵,一共有
其中
embedding维度。注意,item embedding维度和辅助信息embedding维度都设为相同的值。为了融合辅助信息,我们将
itemembedding向量拼接起来,并用均值池化来来聚合itemembedding,即:其中:
itemembedding;itemitem embedding向量或者第embedding向量。所有节点聚合后的embedding构成了embedding矩阵graph embedding矩阵,它是通过DeepWalk算法得到。但是这里辅助信息embedding矩阵通过这种方式,我们融合了辅助信息,使得具有相似辅助信息的
item在embedding空间中更为接近。这使得冷启动item的embedding更为准确(accurate),并提高了离线和在线性能。下图为
GES和EGES的总体架构。SI表示辅助信息(side information),SI 0表示item本身。Sparse Features往往是item ID以及不同SI的one-hot向量。Dense Embeddings是item和相应SI的representation。Hidden Representation是一个item及其相应SI的embedding聚合结果。
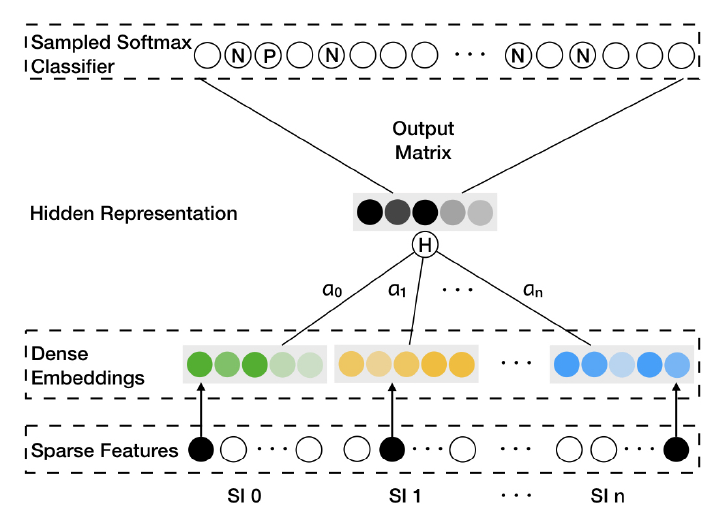
Enhanced Graph Embedding with Side information: EGES:尽管GES的性能有所提升,但是在embedding过程中融合不同类型的辅助信息时仍然存在问题。在GES中,我们假设不同类型的辅助信息对于最终embedding的贡献相等,这不符合现实。例如:购买了iPhone的用户会因为Apple这个品牌而倾向于查看Macbook或iPad;用户可能在同一家门店购买不同品牌的衣服,因为比较方便(convenience)而且价格更低(因为可能存在折扣)。因此,不同类型的辅助信息对用户行为中item共现(co-occurrence)的贡献不同。为了解决这个问题,我们提出了
EGES方法来聚合不同类型的辅助信息。EGES框架和GES相同,它的基本思想是:不同类型的辅助信息在它们的embedding被聚合时有不同的贡献。因此,我们提出一个加权均值池化层来聚合辅助信息的embedding。定义一个加权的权重矩阵
item中,第item embedding自己的权重。itemitem embedding权重。item
注意:这里对不同的节点设置个性化的权重分布,而不是采用统一的权重分布。考虑到
embedding参数数量为embedding参数的那么加权均值聚合的结果为:
这里我们使用
给定节点
embedding。令label(如是否点击),则EGES的目标函数为:我们基于梯度下降法来求解最优化问题,其梯度为:
对于冷启动
item,虽然item embeddingembeddingEGES框架算法:输入:
图
辅助信息
每个节点作为起始点的随机游走数量
随机游走序列长度
Skip-Gram窗口大小负样本数量
embedding维度
输出:
item embedding矩阵和辅助信息embedding矩阵权重矩阵
算法步骤:
初始化
迭代
迭代
通过随机游走得到序列:
执行加权
SkipGram算法:
返回
加权
Skip-Gram算法:输入:
Skip-Gram窗口大小负样本数量
随机游走序列长度
随机游走序列
SEQ
输出:更新后的
算法步骤:
迭代,
正样本梯度更新(
label = 1):更新
迭代,
负样本梯度更新(
label = 0),从
更新
迭代,
未来方向:
首先是在
graph embedding方法中利用attention机制,这可以提供更大的灵活性来学习不同类型辅助信息的权重。其次是将文本信息纳入到我们的方法中,从而利用淘宝
item中大量的评论信息。
1.2 系统部署
这里我们介绍我们的
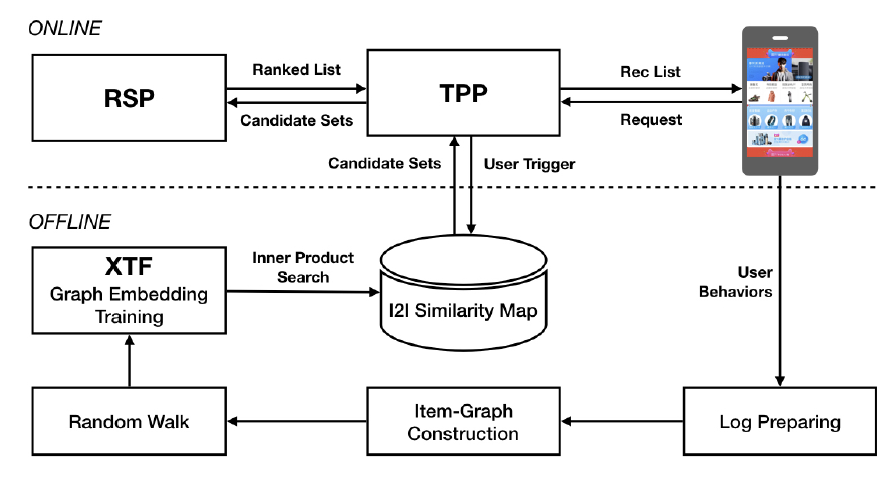
graph embedding方法在淘宝中的实现和部署。我们首先对支撑淘宝的整个推荐平台进行high-level的介绍,然后详细说明与我们embedding方法相关的模块。下图给出了淘宝推荐平台的架构。该平台由两个子系统组成:
online和offline。在线子系统主要组件(
component)是淘宝个性化平台 (Taobao Personality Platform: TPP)和排序服务平台(Ranking Service Platform: RSP)。典型的工作流程如下图所示:当用户打开手机淘宝
App时,TPP抽取用户的最新信息并从离线子系统中检索一组候选item,然后将候选item馈送到RSP。RSP使用微调的DNN模型对候选item集合进行排序,并将排序结果返回给TPP。用户在淘宝的访问行为被收集并保存为离线子系统的日志数据。
实现和部署
graph embedding方法的离线子系统的工作流如下所示:包含用户行为的日志被检索。
item graph是基于用户的行为构建的。在实践中,我们选择最近三个月的日志。在生成
session-based用户行为序列之前,我们会对数据执行反作弊处理(anti-spam processing)。 剩余的日志包含大约6000亿条,然后根据前面所述方法构建item graph。为了运行我们的
graph embedding方法,我们采用了以下的解决方案:将整个
graph拆分为多个子图,这些子图可以在淘宝的Open Data Processing Service: ODPS分布式平台中并行处理。每个子图中大约有5000万个节点。为了在图中生成随机游走序列,我们在
ODPS中使用我们基于迭代iteration-based的分布式graph framework。随机游走生成的序列总量为1500亿左右。
为了实现所提出的
embedding算法,我们的XTF平台使用了100个GPU。在部署的平台上,离线子系统中的所有模块(包括日志检索、反作弊处理、item graph构建、随机游走序列生成、embedding、item-to-item相似度计算)都可以在不到六个小时内处理完毕。因此,我们的推荐服务可以在很短的时间内响应用户的最新行为。
1.3 实验
这里我们进行了大量的实验来证明我们提出的方法的有效性。
首先,我们通过链接预测任务对这些方法进行离线评估。然后,我们在手机淘宝
App上报告在线实验结果。最后,我们展示了一些真实案例,从而在淘宝上深入洞察我们提出的方法。
1.3.1 离线评估
链接预测(
Link Prediction):链接预测任务用于离线实验,因为它是graph中的一个基础问题fundamental problem。给定一个去掉了某些边的
graph,链接预测任务是预测链接的出现。我们随机选择1/3的边作为测试集中的ground truth并从graph中移除,剩余的graph作为训练集。我们随机选择未链接的节点pair对作为负样本并加入到测试集,负样本数量和ground truth数量相等。为了评估链接预测的性能,我们选择AUC作为评估指标。数据集:我们选择使用两个数据集进行链接预测任务,它们包含不同类型的辅助信息。
Amazon数据集:来自Amazon Electronics的数据集。item graph通过 “共同购买co-purchasing“ 关系(在提供的数据中表示为also_bought)来构建,并使用了三种类型的辅助信息:类目、子类目、品牌。Taobao数据集:来自手机淘宝App的数据集。item graph根据前述方法来构建。需要注意的是,为了效率和效果,Taobao数据集使用了十二种类型的辅助信息,包括:商家(retailer) 、品牌、购买力水平(purchase level)、年龄、性别、款式(style)等等。根据多年在淘宝的实践经验,这些类型的辅助信息已经被证明是有用的。
这两个数据集的统计信息如下表所示(
#SI表示辅助信息数量)。我们可以看到这两个数据集的稀疏性都大于99%。
baseline方法:我们对比了四种方法:BGE、LINE、GES、EGES。LINE捕获了graph embedding中的一阶邻近性和二阶邻近性。我们使用作者提供的实现,并使用一阶邻近性和二阶邻近性运行它,结果分别表示为LINE(1st)和LINE(2nd)。我们实现了所提出的
BGE、GES、EGES等三种方法。
配置:
所有方法的
embedding维度均设为160。对于我们的
BGE/GES/EGES,随机游走的长度为10,每个节点开始的游走次数为20,上下文窗口大小为5。
实验结果如下表所示,括号中的百分数是相对于
BGE的提升比例。可以看到:GES和EGES在两个数据集上的AUC都优于BGE、LINE(1st)、LINE(2st)。这证明了所提出方法的有效性。换句话讲,稀疏性问题通过结合辅助信息得到了缓解。比较两个数据集上的提升,我们可以看到
Taobao数据集上的提升更为显著。我们将此归因于Taobao数据集上使用的大量有效且信息丰富的辅助信息。当在
GES和EGES之间比较,我们可以看到Amazon数据集上的性能提升比Taobao数据集更大。可能是因为Taobao上GES的表现已经很不错了,即0.97。因此EGES的改善并不突出。而在Amazon数据集上,EGES显著优于GES。
基于这些结果,我们可以观察到融合辅助信息对于
graph embedding非常有用,并且可以通过对各种辅助信息的embedding进行加权聚合来进一步提高准确性(accuracy)。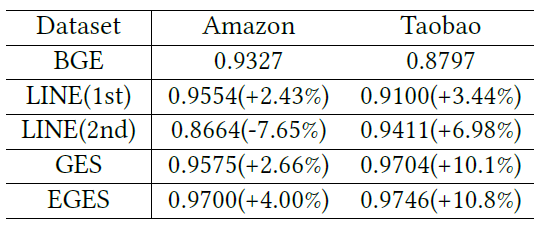
1.3.2 在线评估
我们在
A/B test框架中进行在线实验,实验目标是手机淘宝App首页的点击率(Click-Through-Rate: CTR)。我们实现了上面的
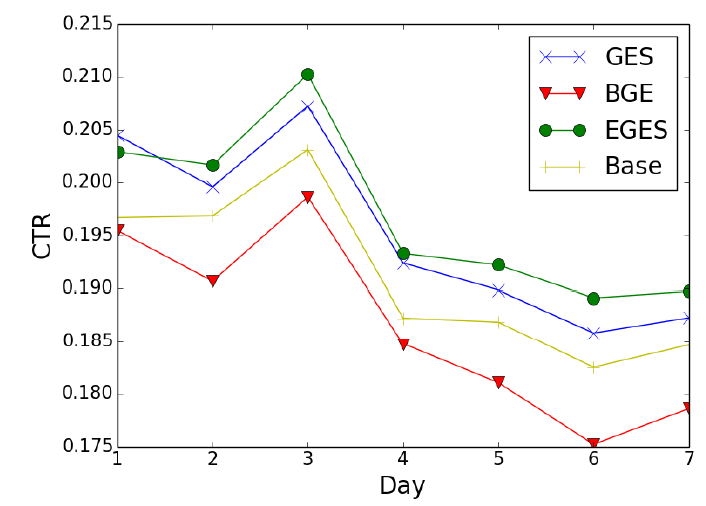
graph embedding方法,然后为每个item生成一些相似的item作为候选推荐。淘宝首页的最终推荐结果由基于dnn模型的ranking引擎生成。在实验中,我们在ranking阶段使用相同的方法对候选item进行排序。如前所述,相似item的质量直接影响了推荐结果。因此,推荐性能(即CTR)可以代表不同方法在matching阶段的有效性。我们将这四种方法部署在一个
A/B test框架中,2017年11月连续7天的实验结果如下图所示。其中,Base代表一种item-based CF方法,在部署graph embedding方法之前已经在淘宝内部广泛使用。Base方法根据item共现(co-occurrence)和用户投票权重计算两个item之间的相似度,并且相似度函数经过精心调优从而适合淘宝的业务。可以看到:
EGES和GES在CTR方面始终优于BGE和Base,这证明了在graph embedding中融合辅助信息的有效性。此外,
Base的CTR优于BGE。这意味着经过精心调优的CF-based方法可以击败简单的embedding方法,因为在Base方法中已经利用了大量人工设计的启发式策略。EGES始终优于GES,这和离线实验结果相一致。这进一步证明了辅助信息的加权聚合优于平均聚合。
1.3.3 案例研究
这里我们展示了淘宝中的一些真实案例来说明我们方法的有效性。这些案例从三个方面来研究:
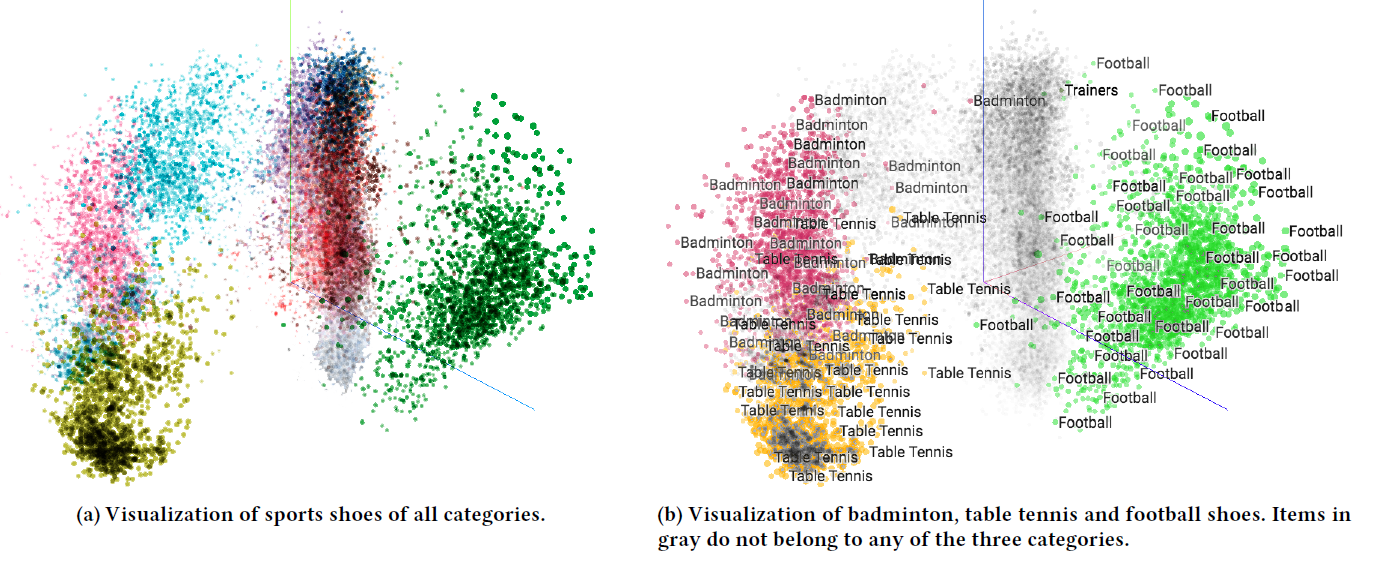
EGES embedding的可视化、冷启动item、EGES中的加权权重。embedding可视化:我们通过tensorflow提供的可视化工具,将EGES学到的item embedding可视化,结果如下图所示。下图为一组随机选择的运动鞋的embedding的可视化,item embedding通过PCA投影到二维平面中,其中不同颜色代表不同的类目。从图
(a)中,我们可以看到不同类目的鞋子在不同的cluster中。这里一种颜色代表一类鞋子,例如羽毛球鞋、乒乓球鞋、足球鞋。这证明了融合辅助信息来学习
emebdding的有效性,即具有相似辅助信息的item应该在embedding空间中更接近。从图
(b)中,我们进一步分析了羽毛球鞋、乒乓球鞋、足球鞋三种鞋子的embedding。我们观察到一个有趣的现象:羽毛球鞋和乒乓球鞋的embedding距离更接近、和足球鞋的embedding距离更远。这一现象可以解释为:在中国,喜欢乒乓球的人和喜欢羽毛球的人有很多重叠。然而喜欢足球的人和喜欢室内运动(如乒乓球、羽毛球)的人,有很大的不同。从这个意义上讲,向看过乒乓球鞋的人推荐羽毛球鞋,要比推荐足球鞋要好得多。
冷启动
item:对于淘宝中的新item,无法从item graph中学习到embedding,并且之前CF-based的方法也无法处理冷启动item。因此,我们利用新item的辅助信息的平均embedding来表示一个冷启动item。然后我们根据item embedding的内积从所有item中检索和冷启动item最相似的item。结果如下图所示,我们给出了冷启动
item的top 4相似item。在图中,我们为每个相似item标注了与冷启动item相关的辅助信息的类型,其中cat意思是category可以看到:
尽管缺少用户对冷启动
item的行为,但是可以利用不同的辅助信息来有效地学习它们embedding(就top相似item的质量而言)。item的门店shop对于衡量两个item的相似性非常有用,这也和下面介绍的辅助信息的权重保持一致。

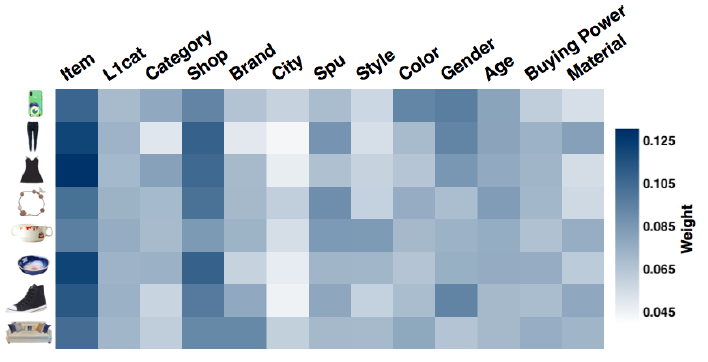
辅助信息权重:我们将
item的不同类型辅助信息的权重可视化。我们选择了不同类目的8个item,并从学到的权重矩阵item相关的所有辅助信息的权重。结果如下图所示,其中每一行记录一个item的权重结果。有几点值得注意:
不同
item的权重分布不同,这和我们的假设相一致,即不同的辅助信息对最终representation的贡献不同。在所有
item中,代表item本身embedding的"Item"权重始终大于所有其它辅助信息的权重。这证实了一种直觉,即item embedding本身仍然是用户行为的主要来源,而辅助信息为推断用户行为提供了额外的提示。除了
"Item"之外,"Shop"的权重始终大于其它辅助信息的权重。这和淘宝中的用户行为一致,即用户倾向于在同一家店铺购买item,这是为了便利性(convenience)和更低的价格(即店铺的折扣)。